|
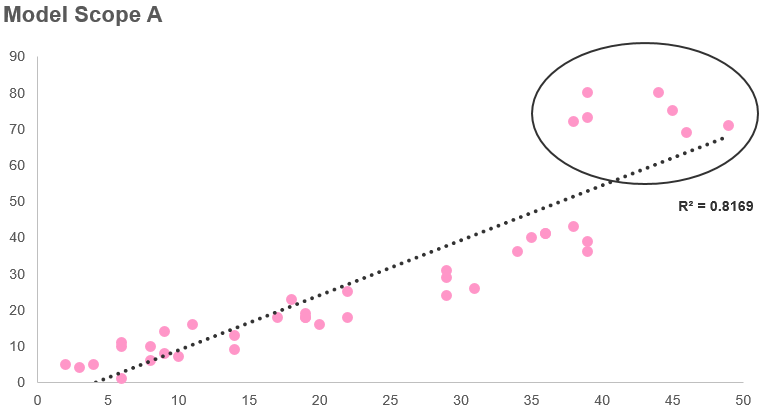
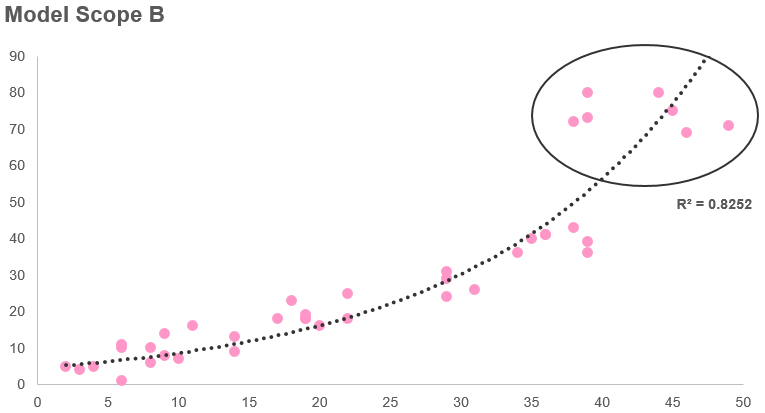
23/6/2019 0 Comments Dealing with outliers
0 Comments
Leave a Reply. |
AuthorLondon SODA
Archives
February 2020
Categories |
|
23/6/2019 0 Comments Dealing with outliers
0 Comments
Leave a Reply. |
AuthorLondon SODA
Archives
February 2020
Categories |


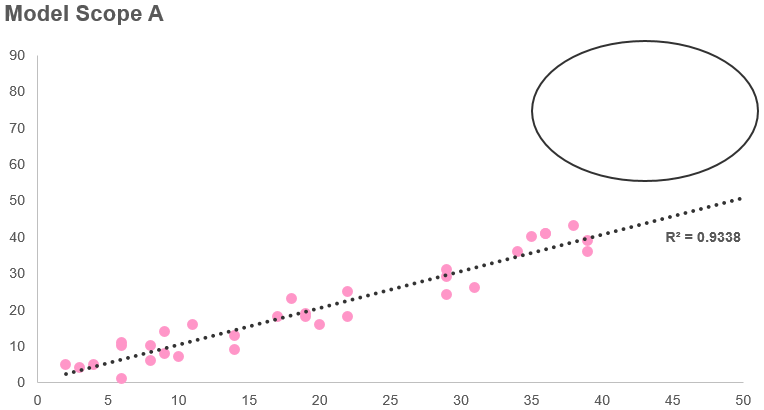

 RSS Feed
RSS Feed